Date:

The article was first published in the April 2026 issue of the World Federation of Exchanges Focus Magazine.
The most important questions about trading platform resilience rarely arise during calm periods – they tend to surface after a production incident, a regulatory audit or a major platform upgrade. These events serve as a reminder of the complex behaviour that financial systems can exhibit under real market conditions.
Our intent in sharing the vital but often delayed questions we've heard over the years is to bring these considerations forward in time, so that hidden risks could be detected earlier. That way trading and post-trade platform operations teams can make deliberate design and operational decisions before those risks materialise – rather than discovering them through regulatory findings or live-market disruption.
‘Our platform has passed internal testing and UAT. Are we client-ready?’
Not necessarily. Passing internal testing or UAT is an important milestone, but it does not in itself guarantee client or production readiness, or operational safety. For instance, UAT confirms that a platform behaves correctly in defined, controlled scenarios. In live operation, however, platforms are exposed to adverse conditions such as complex production scenarios, extreme message rates, price volatility, participant misbehaviour and dependency failures across connected venues, clearing systems and service providers.
From a regulatory perspective – as well as an independent software testing perspective – client readiness is defined by operational resilience, not just functional correctness. Regulators expect firms to demonstrate that critical systems can actively prevent escalations where possible, contain impact when failures occur and recover within defined impact tolerances. This requires evidence beyond UAT sign-off.
A holistic test approach should include stress and capacity testing, failover and recovery testing and validation of system behaviour at the intersection of functional and non-functional features. These should take place in production-like environments mimicking real-user behaviour and the production schedule. These test activities should be supported by robust observability, controls and clear operational accountability.
‘We have been testing all interfaces separately. Is that enough?’
Absolutely not. Problems often emerge between system components and when integrating with other systems – for example, when order placement, execution logic, public market data and internal state feeds interact under timing pressure. Even components that work correctly in isolation can still produce inconsistent or unexpected outcomes in a production-like environment, especially under stress, high volumes or volatility events. A recommended approach is to use end-to-end and integration testing to exercise the full transaction workflow and ensure that components interact together correctly, while potential issues are identified before the production release.
A common coverage gap is cross-stream consistency. Execution records, market data, internal state snapshots and settlement outputs can diverge in subtle ways, unless they are deliberately reconciled against each other as part of pre-release testing, and not just monitored in production.
An example of a recommended practice would be to reconcile matching engine activities with market data streams of several types and with post-trade transactional streams, ensuring that all discrepancies are detected and addressed efficiently.
‘Our regression library is large, and we have full traceability between the requirements and the test cases. Why do we still face defects in production?’
Growing test coverage doesn’t always reflect a deeper understanding of the system under test, so a traceability matrix itself is not a sufficient indicator. As platforms evolve, regression suites accumulate legacy scenarios, assumptions and partial paths. With frequent builds and short delivery timelines, systems are rarely exercised end-to-end under realistic sequencing and load after new functionality is implemented. Comprehensive coverage can only be reliably tracked when a regression library is designed from an end-to-end perspective and keeping in mind edge cases of the functional features, as well as their interactions with each other in production-like scenarios.
Having assessed a given test library, stakeholders may find that:
1) It is run daily but is not known to detect issues;
2) Tests are hard to maintain because each one has to be updated manually;
3) Due to the test library’s massive size, it is hard to understand the validation scope and quickly assess test coverage.
Around last Halloween, a group of our colleagues released a humorous yet revelatory regression library diagnostic heuristic (see ‘Is Your Regression Testing Capability Dead or Alive?’). According to this guidance, signs of a robust regression library include the ability to:
- run continuously,
- detect bugs reliably,
- be reconfigured and deployed across environments,
- integrate with other systems and
- update obsolete functions.
A regression library should only be trusted and scaled if it is categorised as one showing signs of ‘life’.
‘Our system meets all of its initial SLAs. Isn't that enough?’
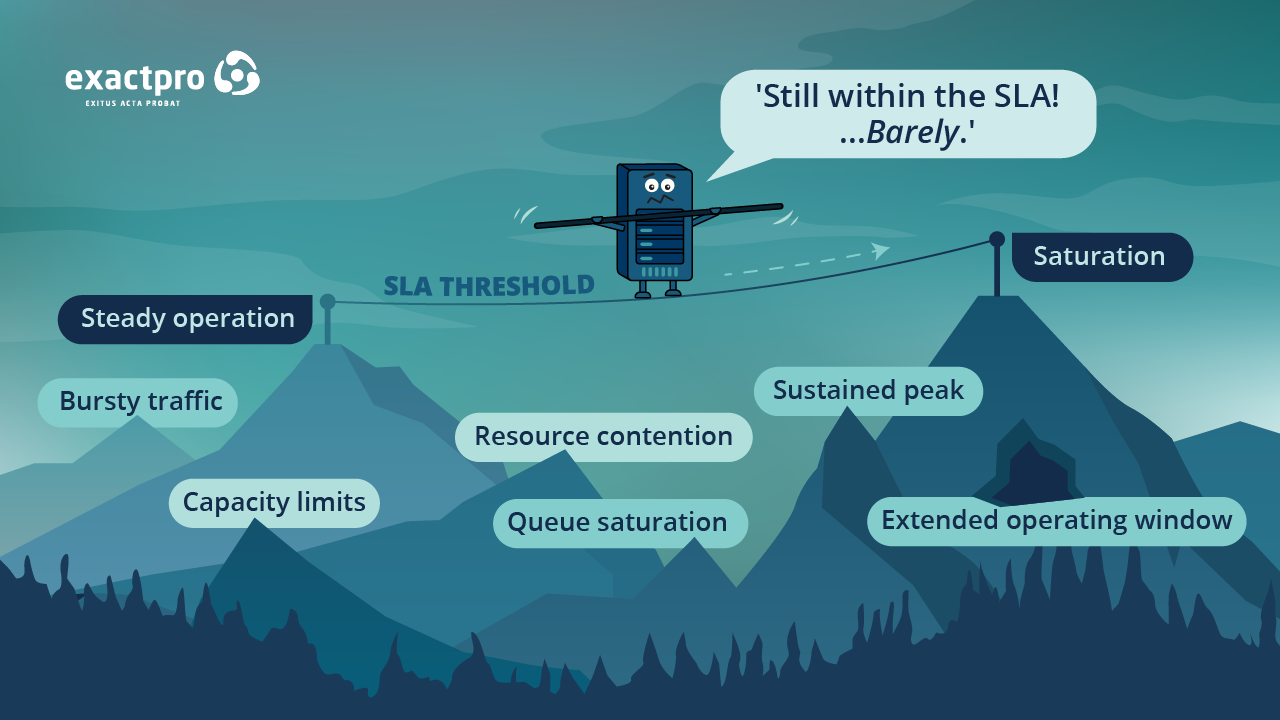
SLAs are a necessary baseline, but not a reliable indicator of operational resilience. They are typically measured using averages or upper-percentile thresholds under steady-state conditions. They convey what the system does most of the time, not how it behaves when conditions deteriorate.
The most consequential failures occur in the margins that SLAs do not capture: latency spikes under bursty traffic, throughput degradation during sustained peak load, resource contention and gradual performance erosion over extended operating windows. A system can remain technically within the SLA, while silently approaching capacity limits.
Regulators increasingly distinguish between SLA compliance and operational resilience. The question is not only whether the system performs within thresholds under normal conditions, but whether it degrades predictably when those conditions are exceeded. Without testing beyond SLA boundaries, compliance can create a false sense of confidence that only holds until real market conditions expose the gap.
‘If something goes wrong, will we see it before market participants?’
In most production incident cases, early signals came from participants or were only discovered retrospectively in post-event analysis, as opposed to in advance, while monitoring the system or in pre-release testing phases. It could simply be because such production-like scenarios had not been tested before, or monitoring dashboards were not part of test execution.
DORA’s Article 10 requires financial entities to implement mechanisms capable of detecting anomalous activities, including ICT-related incidents, and to establish early warning indicators. Meeting this obligation in production is necessary but insufficient: if the same detection capability was not exercised during testing, there is no basis for confidence that it will perform when it matters.
Given the complexity of modern platforms, it is important to include monitoring telemetries throughout test execution to validate not only the system’s behaviour but also its ability to alert operations when an anomaly is detected, as well as its flexibility to allow market operators to take actions preventing undesired consequences.
When it comes to incorporating AI-driven decision-making into financial flows, real-time observability becomes even more important. It should also be enhanced with interpretability and explainability features to allow operators to intervene based on adequate information about the alerted production situation.
‘We've introduced a small change in one component. How can we tell if it affects the whole system and its downstream integrations?’
In most cases, platform owners do not necessarily foresee any challenges after introducing a small change in a single component of a platform. While it may be the case, it poses a threat of underestimating the interdependencies within complex distributed infrastructures and their integrated upstream and downstream systems.
It is crucial to use dedicated test environments recreating a production-like setup to perform integration testing and understand the full impact of any change across internal and third-party systems. The focus is on key areas such as API requests, message routing, error handling and reporting, as well as verification of connectivity across all relevant systems, including CBS links, payment gateways, SWIFT, SEPA and RTGS.
Through capturing the system’s end points traffic, monitoring for anomalies or unexpected rejects and comparing results against expected models, it is possible to detect discrepancies and see how changes reverberate across the financial ecosystem.
End-to-end integration testing should build on this practice. End-to-end test suites should be performed under production-like conditions without relying solely on reference or market data simulators. Additionally, it is recommended to assess third-party platforms, simulating potential negative scenarios wherever feasible to understand the possible limitations in adverse events. This approach allows one to fully understand the impact of changes, maintain operational integrity and have confidence that all systems and integrations will function as intended. We discuss the question of addressing system complexity in more detail in our Post Trade Systems Testing and Test Automation case study.
Conclusion
At Exactpro, we work with FMI teams when they require an independent view on their platform or specific products and need us to identify potential risks – particularly when resilience under real market behaviour is a differentiating factor. Our goal is to provide stakeholders with objective information about the defects and limitations present in their system. This information allows our clients to make timely decisions and avoid unpleasant surprises after go-live.
This list of questions above is a good start to assessing an existing software testing practice, and we hope that our colleagues and counterparts across the World Federation of Exchanges find it useful. If you would like to learn more about our full range of services and read more insights, please visit the Exactpro website at https://exactpro.com/ or reach out via info@exactpro.com to set up a brief introductory meeting.
Alyona Bulda and Dmitry Kolpakov, SVP, Emerging Technologies and Chief Financial Officer, Exactpro