Queries and feedback: Should you have any follow-up queries or feedback, please reach out to Exactpro co-founder and CEO Iosif Itkin at iosif.itkin@exactpro.com or Head of Global Exchanges Alyona Bulda at alyona.bulda@exactpro.com.
Abbreviations
| Abbreviation | Meaning |
|---|---|
| AI | Artificial Intelligence |
| API | Application Programming Interface |
| AWS | Amazon Web Services |
| BBO | Best Bid and Offer |
| CCPA | The California Consumer Privacy Act |
| CPU/GPU/TPU | Central Processing Unit/Graphics Processing Unit/Tensor Processing Unit |
| DDoS | Distributed Denial-of-Service (attack) |
| DLC | Daily Life Cycle |
| DLT | Distributed Ledger Technology |
| EDA | Exploratory Data Analysis |
| EM | Exact Match |
| EOD | End of Day |
| ESMA | The European Securities and Markets Authority |
| ETL | Extract, Transform, Load |
| FAISS | Facebook AI Similarity Search |
| FCA | Financial Conduct Authority |
| FIX | Financial Information eXchange |
| FT | Functional Testing |
| FX | Foreign Exchange |
| GCP | Google Cloud Platform |
| GDPR | The General Data Protection Regulation |
| GPT | Generative Pre-trained Transformer |
| gRPC | Remote Procedure Call |
| HFT | High-Frequency Trading |
| HIPAA | The Health Insurance Portability and Accountability Act |
| IEEE | The Institute of Electrical and Electronics Engineers |
| ISTQB® | The International Software Testing Qualifications Board |
| JWT | JSON Web Token |
| LLaMA | Large Language Model Meta AI |
| LLM | Large Language Model |
| MiFID II | Markets in Financial Instruments Directive |
| ML | Machine Learning |
| MRR | Mean Reciprocal Rank |
| NFT | Non-functional Testing |
| OATS | Order Audit Trail System |
| OAuth | Open Authorization |
| OTC | Over the Counter |
| OTS | One Time Settlement |
| Portable Document Format | |
| PII | Personally Identifiable Information |
| POV | Percentage of Volume |
| RAG | Retrieval-Augmented Generation |
| RBAC | Role-Based Access Control |
| Reg NMS | Regulation National Market System |
| REST API | Representational State Transfer Application Programming Interface |
| ROUGE | Recall-Oriented Understudy for Gisting Evaluation |
| SEC | Securities and Exchange Commission |
| SOR | Smart Order Router/Routing |
| SQL | Structured Query Language |
| SUT | System Under Test |
| TIF | Time in Force |
| TLS | Transport Layer Security |
| TWAP | Time-Weighted Average Price |
| UI | User Interface |
| UTC | Coordinated Universal Time |
| VWAP | Volume-Weighted Average Price |
Reference Documents
| Document |
|---|
| Reference test harness for algorithmic trading platforms, research paper URL: https://exactpro.com/ideas/research-papers/reference-test-harness-algorithmic-trading-platforms |
| Market Data Systems Testing, white paper URL: https://exactpro.com/case-study/market-data-systems-testing-recommended-practices |
| The ISTQB® Certified Tester Foundation Level (CTFL) certification syllabus URL: https://www.istqb.org/certifications/certified-tester-foundation-level-ctfl-v4-0/ |
| The ISTQB® Certified Tester AI Testing syllabus URL: https://www.istqb.org/wp-content/uploads/2024/11/ISTQB_CT-AI_Syllabus_v1.0_mghocmT.pdf |
| The ISTQB® Glossary URL: https://glossary.istqb.org |
| Exchange Simulators for SOR / Algo Testing: Advantages vs. Shortcomings URL: https://www.slideshare.net/slideshow/exchange-simulators-for-sor-algo-testing-advantages-vs-shortcomings/10137512 |
Introduction
As part of its diverse domain expertise in testing complex distributed non-deterministic architectures, the Exactpro team has extensive experience in System Order Router (SOR) testing. SOR is an automated process of handling and executing orders aimed at taking the best available opportunity from a range of different trading venues. SORs have distinctive characteristics that make the technology and the testing supporting it stand out:
- Reliance on context, external sources and outcome optimisation based on a combination of external and internal factors
- Retrieval logic applied to monitor relevant parameters
- Triage and ranking logic applied to the source venues/documents
- Dynamic nature, non-determinism, real-time decision-making
- Separation of the interconnected information retrieval and action modules
- Reliance on historical data to improve future outcomes
The approach used in SOR testing (which are an inherent part of HFT conducted via algorithmic trading venues) – described in detail in our research paper – reflects these unique characteristics, but is also universal enough to be transferred to other systems that possess similar characteristics. As technologies evolve and new systems emerge, we dynamically assess the applicability of the test approach to these new implementations. It has already been successfully transferred from traditional financial systems to DLT technology. In our assessment, it can also be applied to Retrieval-augmented Generation systems (RAGs), including both their AI-based retrieval and generation (LLM) components, as well as their end-to-end validation and quality assessment of their input data and integrations with surrounding systems. In this paper, we will highlight the similarities between SORs and RAGs that substantiate the cross-applicability of the approach, and elaborate on additional testing measures that should be factored in for RAGs.
‘Retrieval-augmented generation’ is defined as a technique for enhancing the accuracy and reliability of generative AI models with information from specific and relevant data sources. RAG-driven generative AI shares the general features of SORs, while also exhibiting distinctive operational features. Their outputs – and, thus, training, testing and validation methods applied to them – are more heavily dependent on domain specifics and the context in which they operate, and their cross-domain transferability is much higher compared to SORs. Nevertheless, according to our assessment, both system types can benefit from the same software quality assessment principles (see a more detailed comparison of SOR-RAG technology features in the next section).
For software testing purposes, we will further draw an in-depth comparison between AI-based systems (with RAG as a key representative) and non-AI-based systems (represented by SORs) based on the universal recommended strategies practiced in the industry. The comparison criteria are aligned with the ISTQB® syllabus for both traditional and AI-based components; they are also accompanied by in-house insights gleaned by the Exactpro team’s experience on active projects.
Based on Recommended Practices in AI-enabled Testing of Algorithmic Trading / Smart Order Router Systems
Are you looking to get an independent assessment of how reliably your system behaves within acceptable risk bounds?
Get in touch for a brief introduction to Exactpro expertise and approaches in creating fully controlled, production-like test environments
High-level Requirements Comparison Table
This section provides a comparison of the SOR and RAG technologies across three types of requirements relevant in the software testing context and set forth for these systems by their stakeholders: functional, non-functional (technical), and regulatory supervision requirements. The section is followed by a more detailed breakdown of the requirements per system type.
It is worth noting that both SOR and RAG systems can have varying degrees of architecture complexity depending on the implementation. In our comparison, we provide a generalised view of both system types and explore relatively advanced levels of complexity in both systems.
| SOR (Smart Order Router) Requirements | RAG (Retrieval-Augmented Generation) Requirements |
|---|---|
| 1) Functional Requirements | |
| Order execution logic and automatic trading | Data indexing and retrieval capabilities Response generation capabilities |
| Market data integration | |
| Liquidity aggregation | Dynamic retrieval (flexibility and adaptability) |
| Asset classes | Multi-source retrieval and knowledge fusion |
| Data normalisation | Relevance scoring and normalisation |
| Customisation of user-specific algorithms and SORs’ flexibility to support them | User Interaction:
|
| Operational requirements | Operational requirements |
| 2) Non-Functional Requirements | |
|
Performance and scalability:
|
Performance and scalability:
|
SOR architecture and design:
|
RAG architecture and design:
|
| Real-time data processing | Real-time data pre-processing Real-time data processing and management |
| Infrastructure environment (including network connectivity schemas for the integrated components) | Infrastructure environment (including hardware) |
| Operational requirements for real-time monitoring and analytics | Operational requirements for real-time monitoring and analytics |
| Security | Security |
| 3) Regulatory and Compliance Requirements (including Ethics for RAG) | |
Regulatory compliance:
|
Bias mitigation
Ethics:
|
Audit trails:
|
Audit logging Transparency Explainability and interpretability |
|
Venue-specific compliance and certification processes:
|
Justifiability Contestability |
| SOR’s certification / onboarding | Industry-specific regulations (e.g., HIPAA for healthcare, SEC for finance), if applicable. |
SOR Requirements
Designing and implementing SORs or trading algorithms requires addressing a comprehensive set of requirements to ensure efficiency, compliance, and optimal execution in financial markets (the complexities of SOR testing are addressed in more detail in these slides, among other Exactpro thought leadership documents). Below we have presented a brief overview of the key requirements covering SORs’ functional, technical, regulatory, and operational aspects. These requirements are derived from industry standards, regulatory frameworks, and recommended practices for high-performance trading systems.
SOR Functional Requirements
- Order execution logic and automatic trading: The SOR should be able to intelligently route orders to multiple venues (e.g., exchanges, dark pools, alternative trading systems) based on predefined criteria like price, liquidity, speed, and cost. Each external venue supports a variety of order types (such as market, limit, stop, iceberg, pegged, and conditional orders) – which should be handled by SORs – and execution instructions / strategies (for example, VWAP, TWAP, Implementation Shortfall, POV, Liquidity-seeking algorithms). Each SOR platform should be capable of receiving external instructions, configuring the instructions for smart order slicing (i.e., when large orders are split into smaller child orders to minimise the market impact and slippage). Also when it comes to the instructions, each external venue is assigned a priority which, in most cases, is dynamically changed based on real-time data (e.g., BBOs, liquidity, fees, latency).
- Market data integration (discussed in more depth in our Market Data Systems Testing case study): Every SOR is integrated with real-time market data feeds available on external venues and market data aggregators (Ticker plants, BBO providers, etc.) for real-time pricing, order book depth, and volume (e.g., Level 1 and Level 2 data). It’s also important to analyse (and, therefore, have access to) historical market data for backtesting and optimising algorithms).
- Liquidity aggregation: The platform should be able to constantly analyse the available liquidity from the connected liquidity pools (public exchanges, dark pools, OTC venues, etc.), including the capability to determine hidden liquidity.
- Asset classes: SOR algorithms may need tailored features depending on the asset class (for instance: for equities, it would be required to handle high-frequency trading, dark pool routing, for fixed-income instruments – to support quote-driven markets and larger, less liquid orders, for derivatives – to manage complex instruments like options or futures with dynamic delta hedging, etc.).
- Data normalisation: Considering the variety of the multiple external trading venues, their market data feeds and differences in static and dynamic reference data that each integrated entity may contain, it is important to standardise these data formats for consistent processing.
- Customisation of user-specific algorithms and SORs’ flexibility to support them: In addition to the existing SOR platform trading algorithms – and their complexity – most systems also support the ability to allow their users to customise the algos in terms of selecting specific asset classes (e.g., equities, options, futures, forex, crypto), user-defined parameters (benchmark prices, risk tolerance, venue preferences, etc.).
- Operational requirements: Operability mainly serves to ensure the SOR or the trading algorithm is practical, maintainable, and user-friendly in a production environment (for instance: the interface for users to submit, monitor, and manage the orders is intuitive. It allows them to easily configure routing strategies, parameters and priorities, real-time visualisation mechanisms for order executions, and market data updates).
SOR Non-Functional Requirements
- Performance and scalability:
- low latency – ultra-low latency (sub-millisecond) for order routing and execution to compete in high-frequency trading environments;
- high throughput – maintaining high volumes of orders and market data without performance degradation;
- scalability – supporting increasing numbers of users, orders, and venues without compromising performance;
- fault tolerance – ensuring high availability with failover and recovery mechanisms to handle system or venue outages.
- SOR architecture and design:
- a modular architecture to allow easy updates, maintenance, and integration of new features or venues;
- an event-driven system to handle asynchronous market data and order events and capable of making a decision based on the processed data and algorithmic logic;
- distributed system design for parallel processing of orders and data across multiple servers;
- a robust API layer for integration with trading platforms, brokers, and market data providers.
- Real-time data processing: SOR systems are required to process and analyse large volumes of real-time market data and pricing feeds efficiently and, at the same time, they should be able to maintain secure, high-performance databases for storing order history, reference data, and analytics.
- Infrastructure environment (including network connectivity schemas for the integrated components): the requirement should also take into account the SOR architecture and design and where the most complex algorithmic logic is placed, in order to allocate the proper hardware resources for specific component needs. Due to the varying nature of the transport protocols (especially when it comes to market data streams), the network diagrams and their configuration correctness requires additional attention.
- Operational requirements for real-time monitoring and analytics: dashboards for monitoring of the SOR’s health, the health of the connectors to the external venues and market data feeds, status of the connections and performance metrics of the platform and its components. In most cases, such dashboards are enhanced with alerting mechanisms for system anomalies, failed executions or regulatory breaches.
- Security – the requirement mainly focuses on handling permutations of data inputs that could exploit security vulnerabilities:
- authentication and authorisation (implementation of the secure user authentication and role-based access control);
- data encryption (encryption of sensitive data (e.g., order details, user credentials) in transit and at rest);
- adversarial testing (simulation of attacks (e.g., DDoS, SQL injection) to verify system resilience, for example: flooding the SOR with invalid orders to test rate-limiting protections);
- input validation (validation of the code for handling malicious inputs (e.g., SQL injection, malformed FIX messages));
- cybersecurity (protection against threats like DDoS attacks, data breaches, and unauthorised access).
Note: the test approach presented below in this document does not cover the security requirement, as it requires a different test approach and set of tools.
In Figure 1, we have provided an illustrated high-level architecture diagram to highlight the SOR platform complexity and variety of the input data sources leveraged by the different components of the distributed SOR systems.
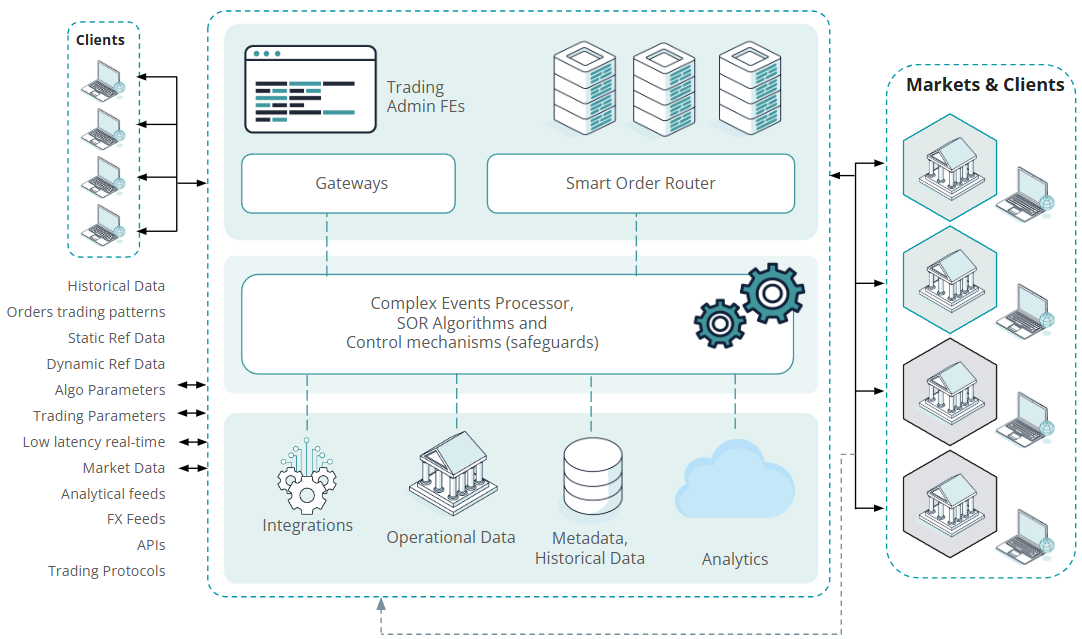
Figure 1: A high-level schema of a SOR architecture
SOR Regulatory and Compliance Requirements
SORs and trading algorithms must comply with financial regulations to avoid penalties and ensure fair trading practices. Therefore, we are also highlighting a set of related requirements here.
- Regulatory compliance:
- best execution to ensure orders are executed at the best available price and conditions (like MiFID II (EU) or Reg NMS (US));
- market abuse prevention to control, detect, and prevent market manipulation (e.g., spoofing, layering);
- pre-trade risk checks to check for position limits, credit limits, and order size restrictions before execution;
- post-trade reporting to generate reports for regulatory bodies, including trade details, timestamps, and venue information;
- transparency rules for pre- and post-trade data, especially for dark pool executions.
- Audit trails:
- record-keeping / logging to maintain detailed records of all orders, executions, and modifications for regulatory audits (e.g., 5-year retention under MiFID II);
- time synchronisation to ensure precise timestamping of orders and trades synchronised with UTC (e.g., within 100 microseconds, as per MiFID II);
- client reporting to provide clients with execution reports, including details on price, venue, and costs.
- Venue-specific compliance and certification processes:
- exchange rules – the specific rules of each trading venue, such as order-to-trade ratios or minimum order sizes, etc.;
- cross-border compliance to ensure compliance with regulations in all jurisdictions where the SOR operates (e.g., SEC, ESMA, FCA);
- Certification and onboarding process at each venue to ensure that the SOR’s connecting component and market data feeds are allowed to connect to the sources.
- SOR’s certification / onboarding process for its own clients (if applicable).
RAG Requirements
In this section, we are highlighting a set of requirements for designing and implementing a RAG system. Reiterating on the note made in the introduction to the paper, we would like to underscore that our requirements and the following comparison are grounded in a generalised view of a RAG system and lean towards a more advanced implementation under test, rather than a Naive one.
RAG Functional Requirements
- Data indexing and retrieval capabilities: Due to the variety of input data and its types, it is important to make sure that the following ML-related RAG capabilities are realised and handled properly:
- knowledge base access – to retrieve relevant documents or data from structured (e.g., databases, knowledge graphs) and unstructured (e.g., text, logs, PDFs) sources;
- indexing – to split databases, documents, logs and other kinds of input data into chunks, to encode into vectors, and to store them in a vector database, to alight the content into hierarchical index structures or knowledge graph indexes;
- query understanding – to interpret user queries accurately, handling natural language variations, ambiguity, and multi-intent queries;
- context-aware retrieval – to incorporate conversational context (e.g., chat history) to refine retrieval for follow-up questions.
- Response generation capabilities: To fulfill the main requirement and support RAG features (with predominantly ML-driven retrieval for embedding and ranking and primarily LLM-enabled response generation), it is important for the system to be able to generate coherent, accurate, and contextually appropriate responses by synthesizing the retrieved information. The actuality and factuality of such responses should also be preserved and grounded in the retrieved documents. In addition to the above, the system should be able to support and adapt the tone, formality, and styles of the responses based on the user preferences or application needs (e.g., professional, conversational, technical). Due to the multilingual nature of its users, it should also be able to handle queries and generate responses in multiple languages, with retrieval from language-specific or multilingual knowledge bases.
- Dynamic retrieval (flexibility and adaptability): It is important for the system to be able to adapt the retrieval strategies based on query type (e.g., factual, analytical, open-ended) in real time.
- Multi-source retrieval and knowledge fusion: The requirement to aggregate information from diverse sources, such as internal databases, web pages, or third-party APIs and be able to merge information from multiple retrieved sources to avoid redundancy and ensure coherence (LLMs are primarily involved in the generation part of the response creation).
- Relevance scoring and normalisation: The RAG system (in particular, the retriever and/or the reranker) should be able to rank the retrieved documents / data based on relevance to the query using techniques appropriate for the task and normalise the different data structures into a format understandable by the LLM.
- User interaction:
- conversational flow with an ability to support multi-turn dialogues, maintaining context across interactions;
- query clarification with an ability to prompt users for clarification when queries are ambiguous or lack sufficient context;
- feedback loop with an ability to let users provide feedback on response quality to improve retrieval and generation over time.
- Operational requirements: To ensure the RAG system is maintainable, monitorable, and user-friendly in production. The system should be user-friendly, with an intuitive interface and an ability to alert the user in case of different error scenarios.
RAG Non-Functional Requirements
- Performance and scalability:
-
low latency – millisecond response times for retrieval and generation, critical for real-time applications;
- high throughput – high query volumes, especially for enterprise or public-facing applications;
- scalability – supporting horizontal scaling to accommodate growing knowledge bases or user demand;
- fault tolerance – ensuring high availability of the system, particularly in production environments where reliability, availability, and user trust are critical;
- resource optimisation – optimising for efficient use of CPU, GPU, or TPU resources to balance cost and performance.
-
- RAG architecture and design:
- modular design – to separate retrieval, generation, and preprocessing components for easy updates and maintenance;
- event-driven architecture – to handle asynchronous user requests and queries;
- microservices – to scale retrieval and generation components independently;
- API integration – to provide APIs (for instance, REST, gRPC) for seamless integration with applications, chatbots, or other systems;
- caching – to access frequently asked queries or documents to reduce latency and computational load.
- Real-time data pre-processing: The requirement to clean and preprocess documents and other input data formats (e.g., remove noise, normalise text) to improve retrieval quality.
- Real-time data processing and management:
- knowledge base structure – to support structured (e.g., SQL, knowledge graphs) and unstructured (e.g., text, PDFs) data formats;
- data storage – scalable storage solutions (e.g., cloud storage, vector databases) for large knowledge bases;
- data versioning – to track changes to the knowledge base for auditability and rollback capabilities;
- active learning – to use user feedback to fine-tune retrieval and generation models.
- Infrastructure environment (including hardware):
- deployment and integration – Cloud and On-Premises Support – to deploy the system on cloud platforms (e.g., AWS, Azure, GCP) or on-premise infrastructures;
- environment monitoring and respective connectivity to the systems’ components;
- hardware requirements for the high-computing components (CPU, GPU, or TPU to allocate where required).
- Operational requirements for real-time monitoring and analytics: dashboards for monitoring of the system’s health, health of the non-AI components and retrieval components, performance metrics of the platform and its components. In most cases, such dashboards are enhanced with alerting mechanisms for system anomalies, failed responses, inappropriate biases, degraded performance, concept drift detection.
- Security – this requirement helps ensure that RAG systems are capable of protecting sensitive data and preventing unauthorised access, critical for applications handling confidential information. These are achieved via:
- access control (implementation of RBAC to restrict access to the knowledge base or system features);
- authentication mechanisms (e.g., OAuth, JWT) for API access;
- data encryption (encryption of data in transit (e.g., TLS) and at rest to protect sensitive information);
- data anonymisation (removal or masking of PII from retrieved documents and queries);
- data privacy (to a degree, encryption of queries, retrieved documents, and responses in transit (e.g., TLS) and at rest);
- adversarial testing (resilience against adversarial attacks, such as prompt injection or attempts to extract sensitive knowledge base data, protections against data poisoning in the knowledge base).
Note: the test approach presented below in this document does not cover the security requirement, as it requires a different test approach and set of tools.
In Figure 2, we have provided an illustrated high-level architecture diagram to highlight the RAG platform complexity and variety of the input data pre-processed and processed by RAGs.
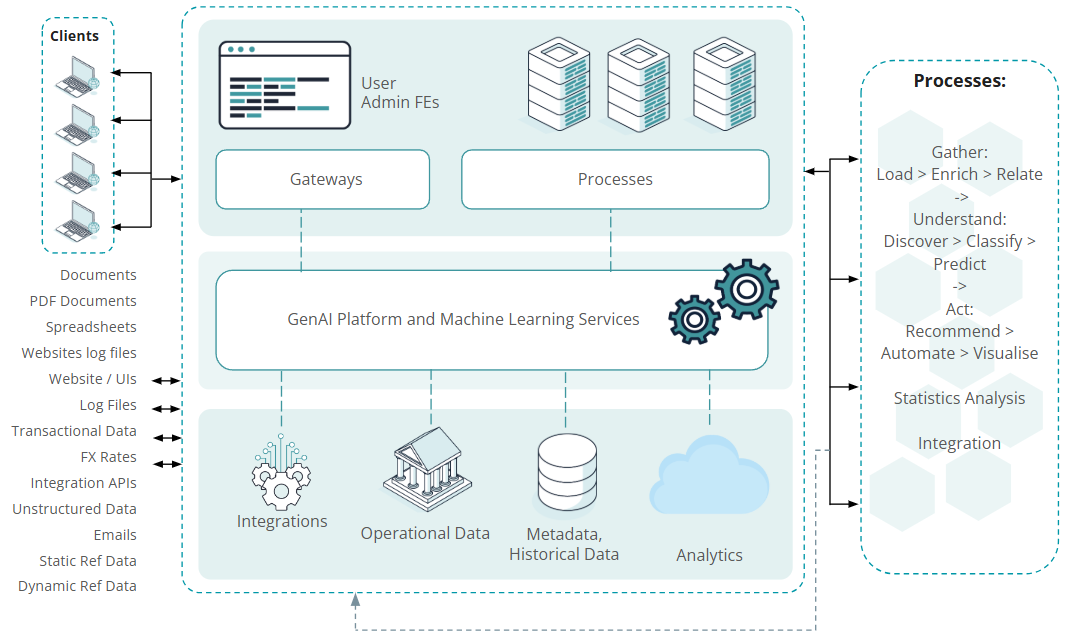
Figure 2: High-level schema of a RAG-driven generative AI architecture
RAG Ethics, Regulatory and Compliance Requirements
- Bias mitigation to detect and reduce biases in retrieval (e.g., skewed document ranking) and generation (e.g., biased language).
- Regulatory compliance – to adhere to regional data privacy laws (e.g., GDPR, CCPA) and industry-specific regulations, including AI oversight. AI regulations emerging globally can be sector-specific or applicable across domains. For instance, the EU AI Act becomes fully enforceable in 2026, affecting all AI systems placed on the EU market and all citizens of the member states – which gives it a global impact. In addition to the regional oversight, the level of regulation of a given system will also depend on its ‘risk category’.
- Ethics – to foster an evolution of ‘trustworthy AI that respects human rights and democratic values.’ As one example, IEEE is working on a range of standards known as 'The IEEE Global Initiative 2.0 on Ethics of Autonomous and Intelligent Systems'. The initiative advocates for embedding ‘safety-first’ and ‘safety-by-design’ principles into AI’s design and lifecycle assessments. It features the IEEE 7000 Series of standards (via the IEEE GET Program™) and related certification tools.
- Audit logging – to ensure all queries, retrievals, and responses are logged for auditing and log integrity is tested and protected against tampering.
- Transparency to indicate when responses (generated content) are based on the retrieved data. This implies having access to the data or algorithm.
- Explainability and interpretability – to provide explanations of retrieval and generation decisions for transparency and trust.
- Justifiability – to provide an understanding of the case in support of a particular outcome.
- Contestability – to ensure that users have the information they need to argue against a decision.
- Industry-specific regulations (e.g., HIPAA for healthcare, SEC for finance), if applicable.
Challenges Accompanying SOR and RAG Systems Testing
The main testing challenges that SORs and RAGs share are rooted in their dynamic nature and the decision-making logic relying on external information sources. These challenges define the unique requirements for the test infrastructure supporting the system. We have also tried to address additional challenges for each of the systems separately. Please see the resulting comparison in Table 1 below.
| Challenges when testing SOR (Smart Order Router) |
Challenges when testing RAG (Retrieval-Augmented Generation) |
|---|---|
| 1) Workflows | |
|
Client order flow complexity and maintenance, while making sure all endpoints are involved (web and thick clients, direct API, and Order Managing Systems). Test coverage of the workflows and complexity of the test scenarios (all order sides, types, TIFs, handling instructions, states, actions, etc.). Test coverage of the scenarios when negative inputs are generated and under the load. |
Workflows within and between the retrieval and generation components of the modular system. Examples of two main components include but are not limited to:
Workflows collecting user feedback for logging and measuring for future performance improvements. |
| 2) Static data and system configurations | |
|
Variety of the static data on multiple trading venues, which should be correctly pre-processed and synchronised on the SOR side:
Due to the nature of the SOR systems being distributed across multiple locations, the proper inter connectivity and components set configurations adds complexity to the test environment and test execution and maintenance. In many cases, it’s also possible to customise SOR itself per the client/user needs, which require customised system configuration testing. |
Before dynamic runtime behaviour can be tested, it is important to check if the system is set up correctly and is stable. Quality of the input data used in training, validation, and testing needs to be checked, this can be done via assessing:
System configuration testing needs to assess if system components, dependencies, and parameters are configured correctly by verifying if:
The retrieval and generation modules need to be validated both separately and jointly (with metrics including but not limited to Recall@K, Precision@K, MRR for the former and EM, F1 score, and ROUGE for the latter). |
| 3) Sources simulation | |
|
External venues simulations:
Diversity of the exchanges:
Simulation of other sources:
|
Synthetic input data simulation to compensate for insufficient data, as larger data volumes are required for proper model training and testing. Additionally, we should make sure that the variety of the simulated data covers all the required input data types (documents, PDFs, log files, spreadsheets, rates, etc.). Simulation of existing IT system integrations and the guardrails put in place for responsible implementation and compliance. Access/permissioning logic simulation (if relevant). |
| 4) Test suite coverage | |
|
Mitigating the limitless number of possible responses by the exchanges to child orders. Mitigating vast amounts of external variables surrounding the process:
Mitigating vast amounts of the race condition events simultaneously happening on the external venues, Market data feeds and SOR itself. If these options are multiplied by the multitude of re‐routing options available to an advanced SOR, it becomes apparent that it is necessary to consider a virtually countless number of test cases. |
The test suite and test results assessment approach needs to be able to verify if:
The input data, their features and its number also should be properly tested:
|
| 5) Scenarios exploring hidden conditions | |
|
Liquidity aggregation with ability to ping/scan for hidden liquidity (when the away markets contain iceberg, hidden, reserved and pegged orders, which are not easy to detect through the market data real-time feeds) implies additional challenge for setting up the preconditions and testing the SOR behaviour. The complexity and amount of the test suites covering the difference in matching rules applicable to the mentioned types of orders and their strategies in trading increases with each difference and variation. |
The operational environment for a RAG system can change over time without the trained model changing and causing the relationship between input data and the desired output delivered by a RAG system may change over time and render a model less accurate/useful – a sign of a concept drift. The input data should also be tested for noise or outliers to avoid inaccurate responses. It is necessary to prevent overfitting, e.g., by comparing a RAG system’s performance on training data versus validation or test data. In addition, data imputation may be used to fill in missing data values with estimated or guessed values (e.g., using mean, median, and mode values). Data acquisition policies should also be reviewed and tested to prevent data poisoning. |
| 6) Reliance on the historical input data | |
| SOR algorithms and their complexity which are based on the historical data and databases, statistics, trading patterns require additional preparation of such data for covering the algorithms. In this case, emulating all of these events will require comprehensive controlled simulators and results analysis. |
Knowledge base changes require ongoing evolution of corresponding tests, lest they become flaky/ obsolete. Retriever over-sensitivity to historical queries can throw off top-k selection and destabilise the test library. Thus, pipe-cleaning the input data, the knowledge base, and the test environment is crucial for correct and stable operation and testing. When it comes to A/B testing and multi-versioning systems, there is a need to execute regression test suites as many times as possible and reconcile the results in-between. Because of the issues which could be there and the number of such executions, this process certainly introduces some challenges in the test process, especially if these validations are not automated. |
| 7) Stochastic nature | |
| Every SOR system contains some degree of the non-determinism (for instance, random events generated for the system accompanied by the concurrency effects and time precision impact). |
Inherent non-determinism in output – stemming both from the retrieving and the generating logic – heavy reliance on training data and sensitivity to the context. There is a need to ensure that AI-based systems are safe (do not harm humans), despite their complexity, non-deterministic and probabilistic behaviours, self-learning capabilities, lack of transparency, interpretability, and explainability, and insufficient robustness. |
| 8) Input data synchronisation | |
|
Comprehensive controlled environment capable of synchronising the end-points (when all input or outputs are located and processed on the different premises). It’s also required to ensure that end-points simulators are compatible with the hosting hardware. The orchestration and time synchronisation of all such codependencies will require additional effort and infrastructure setup. |
In some cases, data points are interdependent – then it is important to make sure they are cleaned, pre-processed, and synchronised accordingly. In this case, it also becomes a challenge, the need for knowledge of the data and its properties and the techniques used for data pre-processing and preparation. The need to check the ETL pipeline organisation: making sure the pipeline collating data from various upstream sources and into a downstream data lake or another target system is configured correctly. |
| 9) Non-functional characteristics measurement | |
|
One of the additional challenges lies with latency measurement, considering components affecting SOR event delays (including networks and firewalls, transport protocols, and system processing). Additionally, the challenges arising while mining the order flow within the system (parent vs child orders, their amends, replenishments, etc.) and searching for the historical data for trading patterns. Due to the multi-component nature and the distribution of components across multiple locations and time zones, the infrastructure requirements supporting such a setup and the necessity to validate the non-functional characteristics becomes a challenge. |
Performance testing for RAG systems is challenging due to their complexity, non-deterministic and probabilistic nature, self-learning capabilities, lack of transparency, and robustness limitations. These challenges manifest themselves via the difficulty to achieve consistent latency, throughput, scalability, and reliability under diverse conditions. High-throughput scenarios demand efficient resource utilisation (for example: a chatbot requiring <500ms latency may struggle to handle 1,000 queries/second without significant hardware resources). |
| 10) Amount of input data | |
|
The real-time data volumes considering the existence of HFT, the amount of such data poses challenges for its processing and analysis in testing, in regulatory reporting (for example, SEC Rule 606 (former Rule 11Ac1‐6) Disclosure of Order Execution and Routing Practices for Non‐Directed Orders, OATS, OTS, MiFID, etc.), the amount of data stored in the historical databases implies the challenge of preparing and controlling this data. |
Heavy reliance on the data volume (on par with its quality and structure) in the reference/input data present in the knowledge base. The necessity to pre-process all input data and its features in an appropriate manner – accompanied by data versioning difficulty. A high risk of partially appropriate retrieval in large corpora. The need to handle large amounts of users and concurrent requests. |
| 11) Environment | |
|
The maintenance of the test environment is challenging, as in most of the cases, SORs are highly customisable solutions with components distributed across several servers connecting to the different sources and venues, for example:
|
Organising/simulating specific conditions in the test environments:
|
Table 1: Challenges accompanying SOR and RAG systems testing
Let us help you mitigate the challenges of your AI-driven financial system
Get in touch for a brief introduction to Exactpro expertise and approaches
Test Strategy Development and Adoption
First, it is important to define ‘software testing’ and determine how its effectiveness is measured. Software testing is an information service. Its goal is to provide stakeholders with objective information about the defects present in their system. A software defect is anything in the code, configuration, data or specification that can decrease the value of software to its stakeholders. Building and operating software without thorough testing is similar to treating patients without accurate diagnostics or participating in electronic trading without access to market data.
The effectiveness of an information service can be judged by the accuracy, relevance, accessibility, and interpretability of the data it is able to obtain over the course of the system exploration and present to the stakeholders. Using a combination of system modelling and AI-enabled software testing allows the Exactpro team to make testing progressively better at detecting and interpreting defects, whilst reducing the timeframes and costs.
As we have observed above, SOR and RAG systems share many similarities that justify applying an existing industry-tested approach to the emerging field of RAG quality assessment. We suggest viewing the testing steps as levels of a multi-level approach. When starting to test SOR systems, it is advisable to pay attention to the testing of input data. This is also true for AI-based systems, as we described above in the requirements and challenges applicable for both system types.
Test Levels
Testing of Input Data
When it comes to SOR SUTs – either connected to the real test environments provided by the exchanges or simulators developed specifically for the controlled testing and non-functional test execution – it also becomes a crucial task to make sure that input data, test cases, and features attributed to them are valid and, when executed, capable for setting the right preconditions and generating the correct expected results. When we consider SOR systems under test, one of the initial tasks is an evaluation of all available end-points to the platform, the protocols they consume, the variety of permutations for field values in each possible message, their sequence and combination. And inevitably, it is required to properly pre-process the input data (including binary traffic in any available format, for instance: tcpdumps, logs) and process it at the injection stage. This includes data preparation for simulators (protocol development, tcpdumps parsing), test case generations based on the external venues’ matching rules and algo strategies and assessing these kinds of data in terms of the coverage and existing gaps, historical data preparation for replay modes in simulators.
In RAG systems, testing the input data and its features implies testing the prompt queries and the datasets / other documents that go into developing the prediction capabilities. Ensuring the quality of both is critical to the operability, robustness, accuracy, and safety of the resulting system. Prompt query testing checks the keyword extraction capacity and ambiguity detection, as well as simulates adversarial behaviour. Dataset and document testing includes but is not limited to conducting static and dynamic testing of the data pipeline (per component and in integration), conducting EDA of the training data and the preprocessing steps, using reviews and statistical techniques to test the data for bias.
Let’s take a look at the possible test validations required to perform with input data of various kinds for RAG systems:
- Testing the retrieved documents and context for quality features (where it is crucial to check whether the content quality is valid, that the completeness of the data is enough, and the data contains all the necessary knowledge to answer the projected queries, that the content is up to date especially in the domains like finance or medicine, that the data is not biased or contains one-sided perspectives, or that the data is not prone to interpretation which could confuse the LLM, etc.).
- Testing the retrieved documents and context for relevance. Usually it involves the design and definition for the evaluation metrics which can be either manual or automated. The validation metrics could be relevant to the topic, whether the semantics correspond to the question, whether it is non-redundant, etc.
- Testing the retrieved documents and context for embedding quality (if using vector retrieval).
- Conducting cosine similarity sanity checks.
- Performing clustering analysis (checking if semantically similar documents embed closely).
- Index coverage tests (checking if every query returns the expected documents).
System Testing (comprising several testing levels)
For the sake of brevity, we are combining model-based testing, component testing, system integration testing levels, and other related sub-processes under this section. However, let's take a pause to introduce model-based testing, as it is not something explicitly described in the ISTQB® syllabus. Model-based testing is the representation of a system or its components in another programming language in a simplified, formal way, to make the aspects of the system / its components clearer, more discernible, and easier to work with. Model-based testing constitutes the core of nearly every Exactpro project; it is applied at all test levels. We accompany such models (a.k.a digital twins) with formal test generation (specifically test generation algorithms to increase the coverage after the quality assessment) and with more formal checks for mechanical execution (where the generated tests are sufficiently precise to efficiently use human involvement).
We consider the system testing level as the main one among all the levels, as system testing is a critical phase in the testing process. It is aimed at validating the end-to-end functionality, performance, compliance, and reliability of the SOR in a production-like environment. Within this phase, we ensure that the SUT meets its requirements (for instance, for child orders being routed to optimal trading venues, processing market data, and adhering to regulatory standards). The following processes are involved in system testing:
- Test design and implementation – test cases creation for functional, non-functional, and compliance requirements using ISTQB® techniques like pairwise testing and others. At this stage, we usually evaluate our existing digital twin (test oracle) capabilities and test cases generation methods to re-use/adapt them for the specifics of the SUT and end-points available for data / test case injection.
- Test environment set-up & maintenance – mock exchanges and market data feeds design, development, configuration and connectivity to them, as well as connectivity to the upstream and downstream components available for integration.
- Test execution – automated and manual tests execution for normal, edge, failure scenarios and other cases requiring special techniques or data pre-processing.
Every process is accompanied with the information about the SUT (defects, incidents, logs, test execution results, versioning, etc.) gathered during the execution.
Note: A digital twin model (a pseudo-oracle when it comes to the RAG area) is usually implemented in a different programming language by different developers for quality assessment purposes.
With RAGs, model testing aims to ensure that the selected model meets any expected functional and non-functional criteria. The former include any acceptance criteria relevant for the model, while the latter feature performance characteristics such as training and prediction speed, computing resources used, ability to handle given numbers of concurrent queries, adaptability, and transparency. Model validation checks whether the ML framework, the choice of the model, its hyperparameters, and the algorithm is most optimal. It also validates the model’s integrations with other AI and non-AI components. Other components including communication networks are also included in this step as it forms an integrated SUT. The AI and non-AI components are then tested for correct interaction. During the system testing step, the functional and non-functional parameters are retested in the context of the ML-based system operating in integration with a complete system and in an environment that is close to the real-life operational conditions. It is especially important if the ML/AI component has been changed (e.g., to reduce the size of the neural network).
Acceptance Testing
Within this level for both types of systems, the process would be very similar and involves domain experts knowledgeable about the SUTs. By defining clear acceptance criteria, using realistic test environments, and incorporating diverse test cases, stakeholders can confirm the system is ready for deployment.
Test Techniques
While the test levels describe where testing activities are focused, the target areas ranging from data sets and models up to full system and acceptance testing, they do not touch upon how those tests should be conducted. To address this, we can apply different testing techniques or perspectives that cut across all levels. These include: white-box, black-box, and data-box techniques (defined in Table 2).
| Term | Definition |
|---|---|
| Black-box testing | (as defined by ISTQB®) is specification-based and derives tests from documentation not related to the internal structure of the test object. The main objective of black-box testing is checking the system's behaviour against its specifications. |
| White-box testing | (as defined by ISTQB®)is structure-based and derives tests from the system's implementation or internal structure (e.g., code, architecture, work flows, and data flows). The main objective of white-box testing is to cover the underlying structure by the tests to an acceptable level. |
| Data-box testing | (as defined by Exactpro) is data-based and derives tests from permutations of the external data that the system relies on in its operation. The main objective is preventing model failures originating from data the models rely on, e.g., bias patterns. |
Table 2: Key Test Technique Terms
These test strategies are applicable to all the test levels mentioned earlier, although the focus and methods will be different at each level. The test techniques used to derive test conditions and test cases for each technique may also differ.
Black-box Testing
Black-box testing for SORs focuses on evaluating the system's functionality, performance, and reliability without knowledge of its internal code or architecture. This approach tests the system from an external perspective, simulating real-world user interactions and market conditions to ensure it meets requirements. By addressing AI-specific challenges like complexity, non-determinism, and lack of robustness, this approach confirms the SOR’s readiness for production.
The black-box testing technique for RAG systems also focuses on evaluating the system's functionality, performance, and reliability without knowledge of its internal code, model specifications or architecture. This approach tests the RAG system from an external perspective, simulating real-world user interactions to ensure it meets requirements for accurate retrieval, coherent generation, and robust operation. By focusing on external inputs, outputs and their interdependencies, this approach addresses AI-specific challenges like non-determinism, complexity, and lack of transparency.
White-box Testing
White-box testing involves evaluating the system with full knowledge of its internal code, architecture, and logic. Unlike black-box testing, which focuses on external inputs and outputs, white-box testing allows testers to examine the internal workings of the SOR to ensure that each component, algorithm, and process functions as intended. Given the complexity, non-determinism, and high-performance demands of SORs, a layered white-box testing technique is essential to systematically validating the system’s internal behaviour, the correctness of the SOR algorithms, their performance, and compliance. The final focus is the same as with the black-box approach.
Similarly to SOR systems, the white-box testing technique for RAG systems involves evaluating the system with full knowledge of its internal code, neural network, architecture, logic, model specification, and what input data was used for its training and evaluation. This approach allows testers to examine and validate the internal components, algorithms, and data flows of the RAG system, to ensure they function as intended.
Data-box Testing
Data-box testing for SOR focuses on testing the system by deriving test cases from permutations and variations of the external data it relies on during operation, such as market data, order inputs, and venue configurations and available reference data. Unlike black-box testing, which focuses on external inputs and outputs without knowledge of the internal logic, or white-box testing, which leverages internal code, data-box testing emphasizes the external data dependencies that drive SORs’ behaviour. This approach is particularly relevant for SORs due to their heavy reliance on dynamic, real-time and historical data (e.g., market feeds, order books, venue statuses) and the need to handle complex, non-deterministic, and probabilistic scenarios and algorithms in financial markets.
The data-box testing technique for RAG systems focuses on testing the system by deriving test cases from permutations and variations of the external data it relies on during operation, such as queries, knowledge base documents, and metadata. Unlike black-box testing, which emphasises external inputs and outputs without knowledge of the internal logic, or white-box testing, which leverages internal code and neural networks, data-box testing focuses on the external data dependencies and data features/factors that drive the RAG system’s behaviour. This approach is particularly relevant for RAG systems due to their heavy reliance on dynamic, diverse data (e.g., user queries, document corpora, real-time feeds) and the need to handle complex, non-deterministic, and probabilistic scenarios in interactions with users.
Test Techniques Comparison Table
Each technique mentioned features specific methods and techniques that contain similarities. Let's take a look at them consolidated in Table 3 (the terms referring to the test strategies and types are used here and onward as defined by ISTQB® in the CI-AI syllabus and the CTFL glossary.
| Testing techniques | Applicable to SOR and RAG | SOR-specific | RAG-specific |
|---|---|---|---|
| Black-box |
|
|
|
| White-box |
|
|
|
|
⇒ To a degree, code coverage and neural network structure coverage techniques serve the same goal – to ensure the coverage internal structure of the specific component which, in the case of a RAG system, could be the complex neural network. |
|||
| Data-box |
|
|
|
Table 3: Test techniques and applicability to SOR and RAG systems
We remember that, although the two system types are quite different in terms of domains and main purposes for their use, they are comparable on the architectural and functional levels, both having similar input-output dependency features and similar logic of the main components. This allows for the logic and the underlying input and output data to be validated using similar techniques. The regulatory environment around RAGs is, at this point, less articulate, so the task of formulating a well-rounded testing framework is paramount. It will address immediate quality assessment and control needs, as well as provide the industry with cutting-edge insights into their comprehensive testing. It is prudent to rely on established industry-tested practices while shaping the approach.
As you can see from the consolidated table above, RAG systems have a lot of similarities with SORs in the test methods and techniques applied at different stages of the SUT and at different test levels, which allows us to transpose the test strategy and test approaches we successfully developed and implemented while testing SORs to RAG systems. The approach accommodates both system types in terms of non-deterministic behaviour and real-time decision-making, the need to process vast volumes of data to come to a desired outcome, and provides the simulation capabilities able to mitigate the systems’ stochastic outputs. In the next sections, we will provide you with the description of these approaches highlighting the aspects which we believe would require some enhancements due to the RAG system nature.
Exactpro’s Test Approaches
In the Figure 3 schema, we provide a high-level illustration of the test approach which has proven itself on many projects and has been enhanced throughout many years of experience in testing mission-critical financial systems (what is understood as ‘traditional’ distributed systems like exchanges, clearing & settlement systems, ticker plants and SORs, and DLT-based platforms).
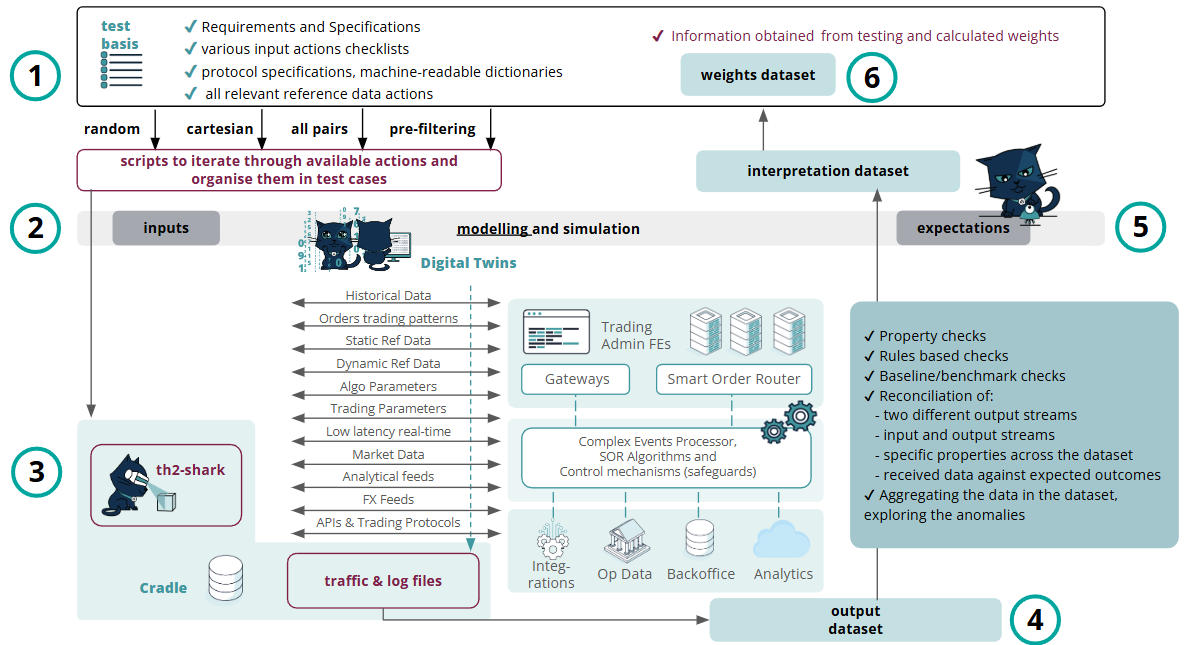
Figure 3: Exactpro’s test approach for SOR systems testing
We will not go deep into the steps description of this approach at this point, but rather show that the same concept can be reapplied with a focus on a RAG system. Let’s take a look at Figure 4 where a RAG SUT is shown instead of a SOR one:
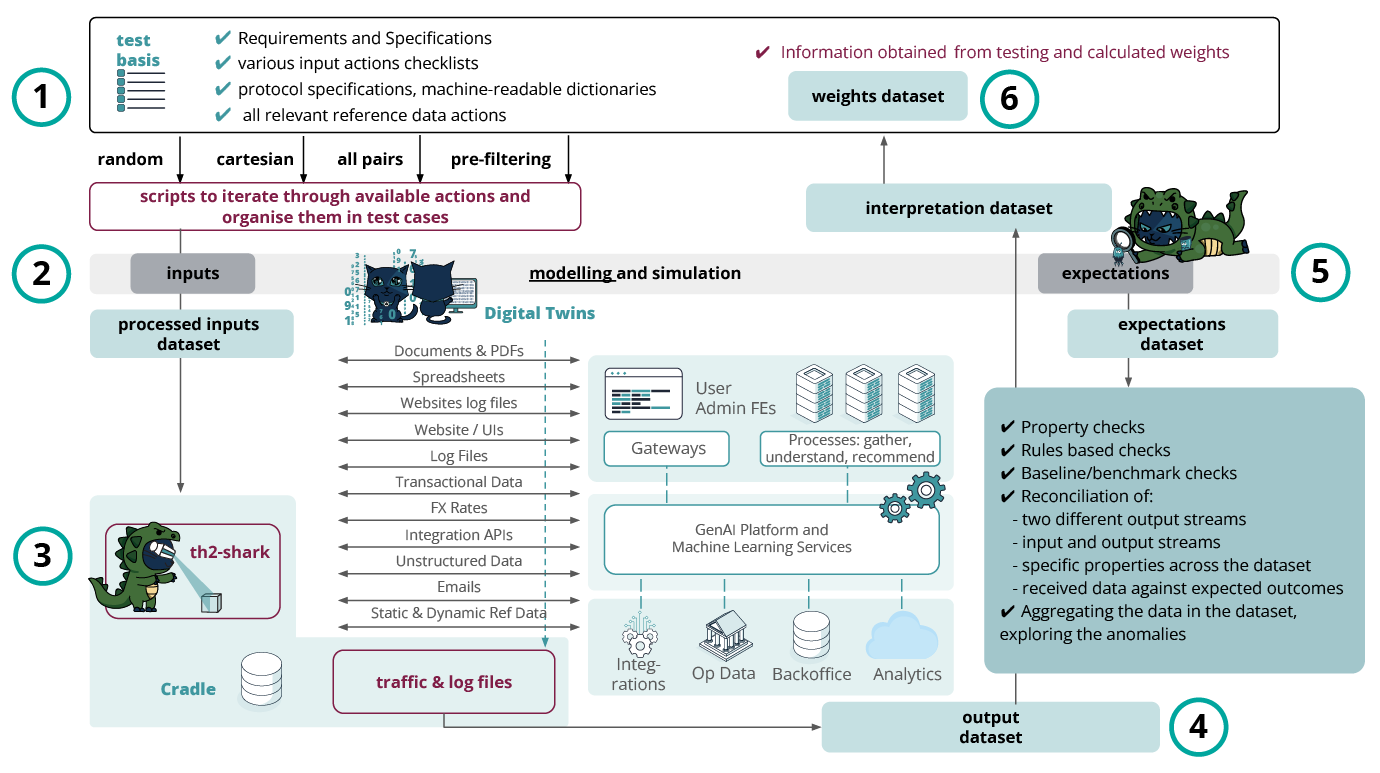
Figure 4: Exactpro’s test approach for RAG systems testing
As you can see, the test approach here combines the multi-layering and involves the same set of steps, with the exception of the data kinds that are being pre-processed, processed, and injected into the SUT.
The generalised domain-agnostic approach involves the following steps:
1. Test basis analysis – analysing the data available from specifications, system logs and other formal and informal sources, normalising it and converting it into machine-readable form.
As can be seen from the requirements section, the nature of the input data and its features is different in some cases, however when you look at the comparison table below (see Table 4), it is easy to draw similarities, and it is obvious that requirements and specifications are something the test team work with on a day-to-day basis when testing both system types.
| SOR specific input data | RAG specific input data |
|---|---|
|
|
Table 4: SOR- and RAG-specific input data
In order to support test basis pre-processing and data input preparation, the initial set of validation checks are performed to the multiple variations of the kinds of inputs and their features, for instance:
✔ various input actions checklists;
✔ protocol specification/requirements, machine-readable dictionaries;
✔ all relevant reference data actions;
✔ input data generation using pre-filtering, all pairs, cartesian, random variation;
✔ execution of the scripts to iterate through available actions and organise them in test cases.
2. Input dataset & expected outcomes dataset – the knowledge derived from the test basis enables the creation of the input dataset used further for test execution. It also lays the foundation for modelling a ‘digital twin’ of the SUT – a machine-readable description of its behaviour expressed as input sequences, actions, conditions, outputs, and flow of data from input to output. The resulting expected values dataset further helps reconcile the data received from the SUT during testing with the pre-calculated expected values.
We should also make a note of the need and possibility to develop/update existing input data simulators. If there is a need to balance input data in terms of the variety, its kinds or specific features (either dynamically or statically generated), it also becomes a part of this step.
3. Test execution, output dataset – all possible test script modifications are passed on for execution to Exactpro’s AI-enabled framework for automation in testing. The framework converts the test scripts into the required message format, and, upon test execution, collects traffic files for analysis in a raw format for unified storage and compilation of the output dataset.
4. Enriching the output dataset with annotations – the ‘output’ dataset is attributed annotations for interpretation purposes and subsequent application of AI-enabled analytics. This also enables the development of the interpretation dataset – a dataset containing aggregate data and annotations from the processed ‘output’ and ‘expected outcomes’ datasets in Steps 4 and 5.
5. Model refinement – this step plays a major role in the development of the ‘digital twin’. Property and reconciliation checks in iterative movements between Steps 4 and 5, the model logic is gradually trained and improved to provide a more accurate interpretation of the ‘output’ dataset and to produce updated versions of the ‘expected outcomes’ and ‘interpretation’ datasets.
Below are listed the property and reconciliation checks which are usually executed against the data collected during test execution:
✔ property checks;
✔ rules-based checks;
✔ baseline/benchmark (A/B testing) checks;
✔ reconciliation and interdependencies of:
- two different output streams;
- input and output streams;
- specific properties / features across the dataset;
- received data against expected outcomes;
✔ aggregating the data in the dataset, exploring the anomalies.
6. Test reinforcement and learning. Weights dataset – discriminative techniques are applied to the test library being developed, to identify the best-performing test scripts and reduce the volumes of tests required for execution to the minimal amount that, at the same time, covers all target conditions and data points extracted from the model.
The final test library is a subset of select scenarios that are iteratively fine-tuned until the maximum possible level of test coverage is achieved with the minimal reasonable number of checks to execute. Carefully optimising a subset of test scripts results in achieving a significantly more performant and less resource-heavy version of the initially generated test library.
Unified storage of all test data in a single database enables better access to test evidence and maximum flexibility for applying smart analytics, including for reporting purposes. The final test coverage report helps demonstrate traceability between the requirements and the test outcomes.
Test Coverage Assessment
Our Market Data Systems Testing case study contains an in-depth dive into the advanced methods of test results analysis. Despite the fact that it is focused on market data systems under test, this assessment approach can be easily re-applied to RAG systems.
The assessment of test inputs, outputs and, therefore, test coverage is an important part of the RAG systems testing process. We consider the input data unit – with its specific features influencing the RAG system outputs – a ‘coverage point’. And our goal here would also be to check as many relevant coverage points – in the units of data available at hand – as possible, with the minimal reasonable hardware and time resources spent.
The overall test coverage encompasses validations performed at each testing level through each test approach applied (similar to that of any traditional non-AI system). Each coverage point is evaluated through the values and features of the data accepted by the system. Obviously, the resulting coverage assessment system is a multi-layer framework. It comprises a function derived from coverage measures of each coverage data point within the validation layer, times the number of validation layers. The results of such a function – along with the input, output data, its features, and RAG behaviour evaluation collected with test executions – form the coverage evaluation framework.
In Figure 5 we schematically address a coverage evaluation framework intended for the RAG SUT, highlighting the areas uncovered by validation layers and overlapping areas of the validation layers. The overlap here is caused by some coverage data points being targeted by the multi-layered approach in several types of validations, ensuring deep and comprehensive system exploration.
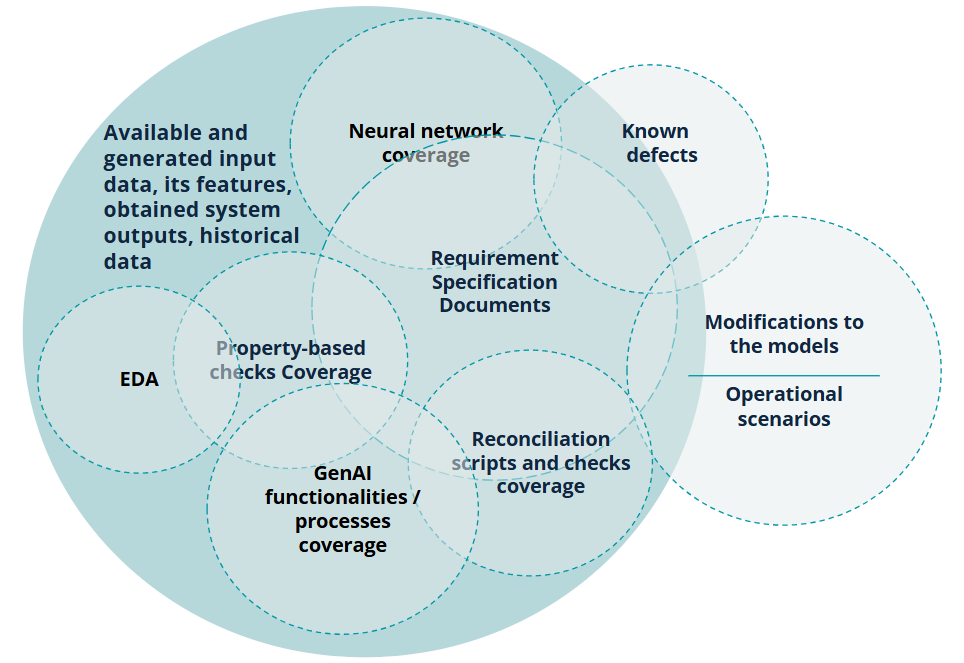
Figure 5: Test Coverage Evaluation Framework for a RAG SUT
This approach highlights the coverage of RAG system behaviour, its data sources, and data itself, which can also be automated for the visualisation, parametric results analysis and reporting, and other testing and stakeholder needs. The proposed test coverage evaluation framework enables advanced system exploration across the multiplicity of strategic validation layers, complementing the requirements specification documents coverage analysis and other more formally prescribed methods that are especially widespread in regulated industries.
Conclusion
This paper provides a detailed analysis of the requirements for SOR and RAG systems, two complex, data-driven systems critical to their respective domains of financial trading and AI-driven information retrieval, respectively. Through consideration of the testing strategies: black-box, white-box, data-box, and system testing levels, we have highlighted the unique challenges of each system, including complexity, non-determinism, lack of robustness, and regulatory compliance for SOR and RAG systems. The comparison reveals shared needs for the input data validation, system testing, performance optimisation, and fault tolerance, despite the differences in their operational contexts.
A key insight from this analysis is the applicability of Exactpro's fine-tuned AI-enabled testing approach for SOR systems to RAGs. This approach, characterised by structured testing steps and quality assessment metrics, has proven effective in helping ensure SOR reliability, compliance, and performance under dynamic market conditions. By leveraging the many years of experience and domain knowledge accumulation, the approach efficiently addresses SOR-specific challenges, such as probabilistic routing and regulatory mandates.
With targeted modifications, this enhanced testing approach can be successfully reapplied to RAG systems. Adjustments include adapting input data pre-processors, simulators of input data generation, test cases to focus on query processing, retrieval accuracy, and response coherence, incorporating data-box testing to handle diverse knowledge base inputs, and enhancing compliance testing for data privacy (e.g., GDPR). The modifications should address RAG-specific challenges, such as probabilistic retrieval and lack of transparency, while preserving the approach’s strengths in structured validation and defect management. By applying this proven, adaptable testing framework, we can ensure robust, reliable, and compliant RAG systems, mirroring the success achieved with SORs.
Key Takeaways
The non-deterministic, multicomponent, distributed architecture shared by Smart Order Router (SOR) and Retrieval-augmented Generation (RAG) systems prompts the urge to explore parallels between the two. The multi-aspect analysis of the two system types – namely their the high-level architectures and the functional/ non-functional and regulatory requirements set forth for these systems by their stakeholders and relevant in the software testing context – has allowed us to conclude that the test approach and frameworks historically applied to SOR systems in the financial domain can be capitalised on when assessing the quality of RAGs.
RAGs are a more recent technology, compared to SORs, and regulation around them is not yet robust, so the task of formulating a comprehensive testing and test coverage assessment frameworks are paramount. It can address immediate quality assessment and control needs, as well as provide cutting-edge insights into their thorough testing that would help anticipate compliance needs. That is why it is especially prudent to draw from established industry-tested practices while shaping the approach for RAG quality assessment.
Based on these assumptions, Exactpro’s well-established industry-proven recommended practices for software testing, and the results of our comparison, the paper presents a reference test strategy for RAG systems. It outlines both the aspects shared with a strategy and test layers for SORs, and the targeted modifications that need to be undertaken uniquely for RAGs. These include but are not limited to adapting input data pre-processors, simulators of input data generation, test cases to focus on query processing, retrieval accuracy, and response coherence, incorporating data-box testing to handle diverse knowledge base inputs, and enhancing compliance testing for input data.
About Exactpro
Exactpro is an independent provider of AI-enabled software testing services for financial organisations. Our clients are exchanges, post-trade platforms, and banks across 20 countries. Founded in 2009, the Exactpro Group is headquartered in the UK, has operations in the US, Georgia, Sri Lanka, Armenia, Canada and Italy, and a global distributed network of technology consultants.
Exactpro is involved in a variety of transformation programmes related to large-scale cloud and DLT implementations at systemically important organisations. Our area of expertise comprises API gateways, matching engines, market data, clearing and settlement, market surveillance, helping improve functional and non-functional system parameters.
To explore the application of the AI Testing approach to your AI-driven infrastructure, book a demo or get a more general introduction to how Exactpro expertise is helping firms boost the operational resilience, performance, and knowledge of the intricacies of their mission-critical systems, reach out to us via info@exactpro.com. Learn more at exactpro.com or follow us on LinkedIn and X.