Date:
Exactpro is an open access quality assurance branch of the London Stock Exchange Group.
Exactpro employs over 360 people and is mostly focused on software testing. We build software to test software and this article is focused on machines that test. But what about machines that think? Should software testers be concerned about machine learning?
Advances in data analysis and artificial intelligence rapidly change the world around us. The presence of machines that think will soon affect all industries, processes and occupations.
Computers can recognize a cat on the screen. Why can't they recognize a bug in the code or an anomaly in inbound messages? An algo can control a real car. Surely, it can control the test environment, independently deploy software and perform a check for red flags. They say that there is not a single presentation on the subject without a killer-robot picture.
On the other hand, there are people who relentlessly torture software, break it and criticize it, subject it to ruthless procedures like soak and negative testing, and sometimes even prevent it from being released into the Wild. How do we call these people? Butchers? Murderers? No, they are called Software Testers.
Machines were created by the humans to make life easier. One day software will take over the world. When that day comes, will there be any particular category of people who will be considered war criminals by our new robot overlords? Certainly. So it is not just a question of losing your job, and death might not be our biggest concern after everything we have done to software.
But let's be more optimistic. What can we do to bring this bright moment forward? As there are four fingers on these hands below, there are four points that are worth bringing up:
-
Software development life cycle
-
Key enablers for machine learning in testing
-
An approach to improve the test libraries
-
Challenges with real-time systems
Software development lifecycle normally starts with defining the Requirements, followed by elaborating Design and Code and ends in detecting Software Bugs. However, there is one rigorous process in-between and that is called Magic.
Exactpro can be compared to a large refinery that, using requirements and code, turns them into a large set of defects along with their descriptions, aimed at making software pure and ready for use. We have over ten thousand software defects reported against each of our main markets and related systems. This is what is called big data in software testing.
Some of this data set is in the natural language - like the subject and the description, it being the essence of software defects. But all of it is accompanied by many structured tags' severity, priority, time to fix, status, component, places that were changed in the source code, etc.
Plenty of insight can be obtained from analyzing the entire defect repository and looking at it as a big data set. For instance, clearing and settlement systems are much more prone to software defects. Data set analysis will immediately confirm that between a trading system and a clearing system, the latter is substantially more complex and error-susceptible.
According to research, looking into big data sets of defects allows us to do the following:
-
Predict the probability of a defect being re-opened
-
Highlight the area of the code where the bug is most likely located
-
Identify requirements and areas most prone to defects in the next software release
This is already within our grasp and even superficial research into the subject will reveal at least thirty papers, analyzing static testing and defects repositories, and applying machine learning to this area.
As for dynamic testing, what is required to enable machine learning in this area?
A. First of all, a lot of data is required for it to be informative. To produce it, the test tools should be able to sustain high volumes of test automation. Essentially these should be non-functional testing tools.
B. Secondly, machine readable specifications are a must. Technically, OCR could be used to go through PDF protocol specifications, but it is hardly the best way to allocate processing resources. It is much more sensible to have them go through various combinations of inputs.
C. Thirdly, to store the data, production-scale passive testing capability or market surveillance systems are much needed to gather the data, required for learning.
D. Lastly, it is necessary to build the systems with testability in mind' at the very least you need to ensure being able to deploy, start, restart and configure it automatically in order to run them regularly.
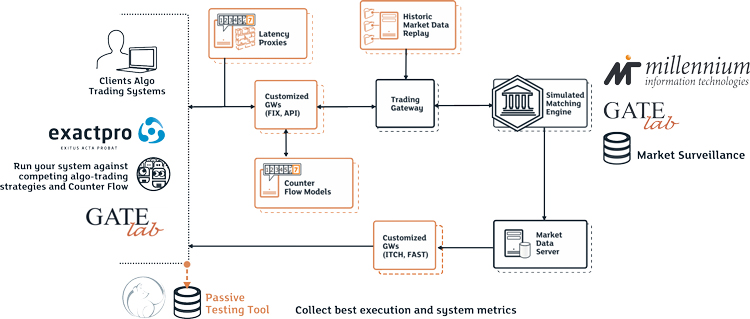
This is a sample test harness that we can use to validate trading algorithms. High scalability and performance, as well as automatic management allow running the tests multiple times a day automatically. A certain algo can be tested against both market replay and competing algorithms, produced by the test tools, or other algo trading systems. However, the time spent doing that is still too limited time for the infinite number of possible permutations.
That is when machine learning techniques come in to help optimize the testing subset based on the following:
-
Defect database
-
Code coverage
-
And their ultimate combination'Mutation Testing
Therefore, it is possible to take an infinite number of tests and organize them into reasonable subsets that can be executed one by one. However, this alternate test execution is not rational when dealing with the real-time systems.
It would be much more sensible to run these tests in parallel. This way the probability to reveal some issues is much higher, this specifically concerns the issues that are hard to locate, using conventional test automation methods. Additionally, passive testing can be used to help detect a problem within a huge data set. Although it is highly problematic to control the state of individual test cases then. How can we tell what was actually covered and what was not? How can we teach a machine to recognize the test scenarios used to make another machine produce a semi-random load against the system under test?
This is a substantially more challenging task, compared to some weak artificial intelligence activities, described earlier, and it is currently one of the main directions of research at Exactpro. Once we learn how to understand what exactly was executed, we will essentially teach the system to produce and execute test scenarios by itself.
Getting back to the robots, Google DeepMind published a paper claiming that it is possible to introduce a button to interrupt undesired behavior of most of the learning algos in such a way that they will not learn to prevent operators from intervening, if necessary. This seems promising. The only problem is that the research is based on the assumption that the algos will not learn from regular intervention. What about the first intervention? Once we have brand new software, will we still have enough time to press the button?
Science fiction teaches us that the only way to survive the robo-apocalypse is to have a friendly robot, which will protect you from its peers. When we build software to test software we need to make sure that it is friendly enough and adapts to our values.

